NewgenONE Platform
Data Fusion Hub
Visually prepare data at a massive scale.

Leverage an intuitive visual interface to easily prepare data at a massive scale for enterprise-wide analytics and machine learning initiatives. Ensure the reliability of results by validating the data for accuracy and consistency. Furthermore, perform various data operations, such as blend, curate, and wrangle for creating and scaling data pipelines with in-built connectors
Data Fusion Capabilities of NewgenONE Platform
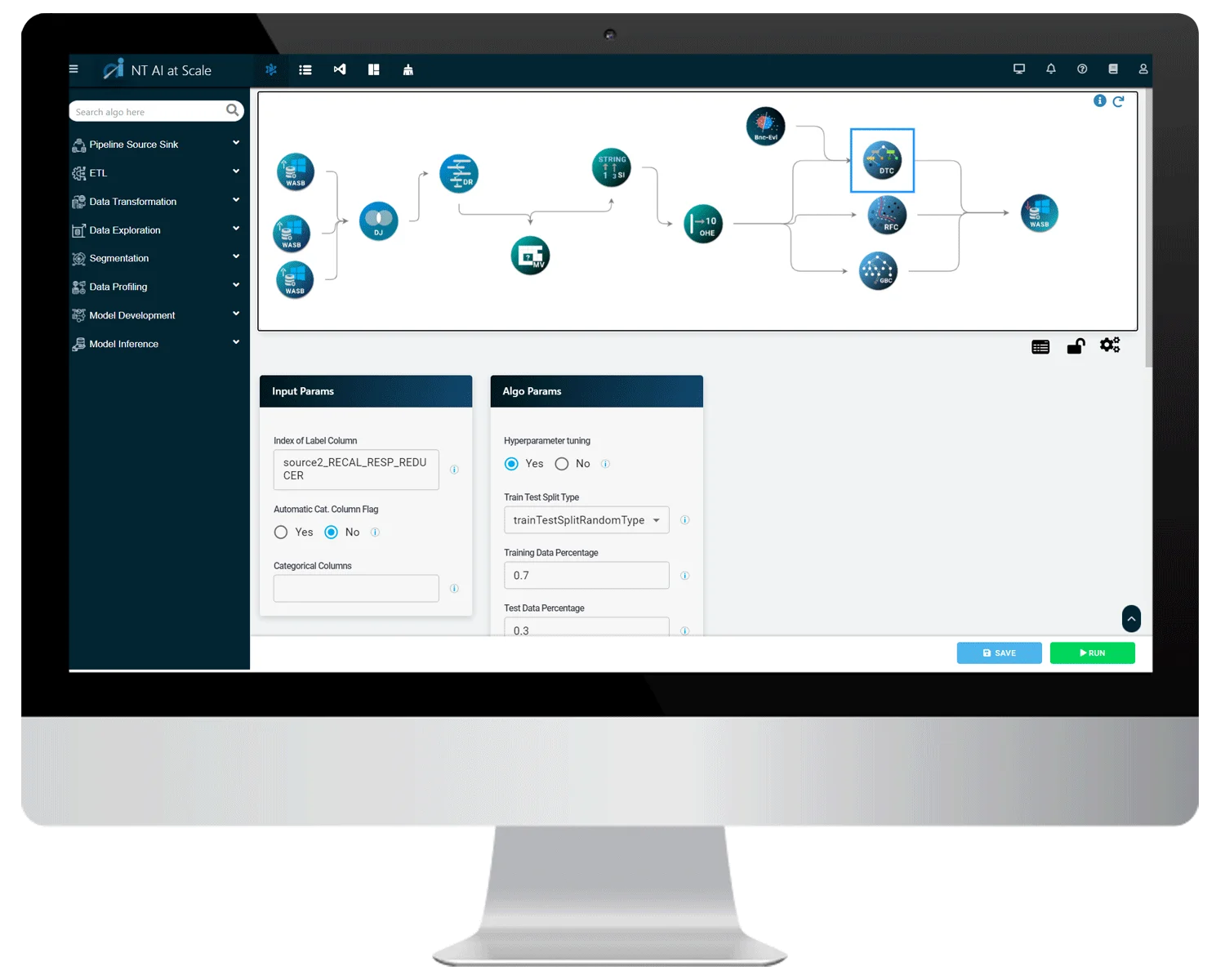
Blend and Curate Data with Ease
Utilize multiple data sources, including, NoSQL database, relational database, BLOB, real-time queue, etc., using in-built connectors
Prepare data visually and apply joins across multiple data sets and sources
Prepare massive-scale data through distributed extract, transform, and load (ETL) capabilities
Save the prepared data in multiple sources, including Hadoop, BLOB, elastic search, etc.
Wrangle Data to Create and Schedule Data Pipelines
Perform various operations on data, including extraction, filter, transform, and group by filters
Leverage the existing capabilities to create new features
Schedule and run the complete data pipeline seamlessly on new datasets using the distributed compute
Handle Large-scale Data with Ease
Utilize in-memory distributed data virtualization to manage large-scale data instead of locally storing a copy
Prepare and process large-scale data as a horizontally scalable platform
Scale Data Pipelines with In-built Data Connectors
Save the prepared data in multiple sources, such as Hadoop, Blob, and other file systems
Integrate multiple data formats, including relational, NewSql, NoSql, etc.
Reuse visual data pipelines and share them further across the team and other users



























