NewgenONE
Intelligent Data Extraction
Gain actionable information with Intelligent Data Extraction from documents for faster processing.

Intelligent Data Extraction enables quick extraction of critical data from paper and digital documents to streamline your content-driven processes, reduce errors, and enhance operational efficiency. Aggregate documents from disparate sources, make them legible, and intelligently extract data precisely while continuously improving extraction accuracy. Intelligent Data Extraction enables data extraction and redaction from identity documents using artificial intelligence and machine learning (AI/ML).
Intelligent Data Extraction Capabilities of NewgenONE Platform
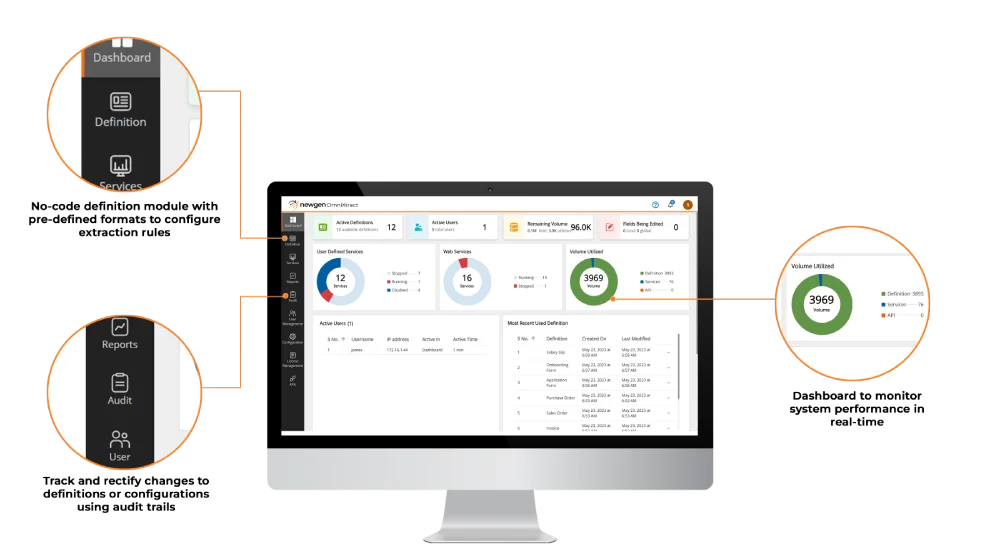
Automated Intelligent Data Extraction and Verification
Pre-trained and trainable models for invoices with the ability to build new models based on business requirements
Automated interfaces for quick and accurate intelligent data extraction and verification
Real-time and error-free data for informed decision-making
Support for multiple extraction technologies, such as ICR, OMR, OCR, barcode, and MICR
Intelligent Image Processing and Data Formatting
Automatic detection and correction of image distortions, enablingreal-time quality improvements in single or multi-page scanned documents
Validation of extracted data and post-extraction formatting
Historical data analysis for better extraction accuracy
Intelligent Document Definition
AI/ML model for creating extraction template definition easily
Low code capability to define document types with varied layouts
Pre-configured document types from various verticals for quicker implementation
Concurrent multi-user support for collaborative definition creation
Reports and Visualization
Intelligent Data Extraction enables Contextual reports and dashboards to gain insights into various accuracy levels
Image-assisted output analysis, with real-time monitoring of extraction throughput and accuracy trends
User activity logs to track all changes made in any module
Identity Document Recognition, Extraction, and Redaction
Identification of entities based on name, date of birth, ID number, etc., and classification of recognized entities
Support for identifying, locating, deciphering, and extracting QR codes and MRZ in identity documents
Extraction of textual entities using OCR after processing the identity document image
Redaction of classified entities to hide personal identifiable information
Confidence Levels and Customized Models
Accuracy measurement of entity identification and extraction through localization and OCR confidence percentages
Intelligent Data Extraction capability enables creation of use case-specific analytics models with a collection of samples























