NewgenONE Platform
AI-first Content Classification for Intelligent Organization
Use AI-first content classification to automatically categorize documents by structure and text, enabling smarter decisions, improved productivity, and seamless content management for an enhanced customer experience.

Automatically classify documents based on structural and textual characteristics to streamline content management operations. Leverage AI-first and machine learning technologies for layout-, object-, and content-based classification. Provide contextual information access to enable smarter decision-making, boost productivity, and deliver superior customer experiences.
Why Should Enterprises Choose NewgenONE platform for Content Classification?
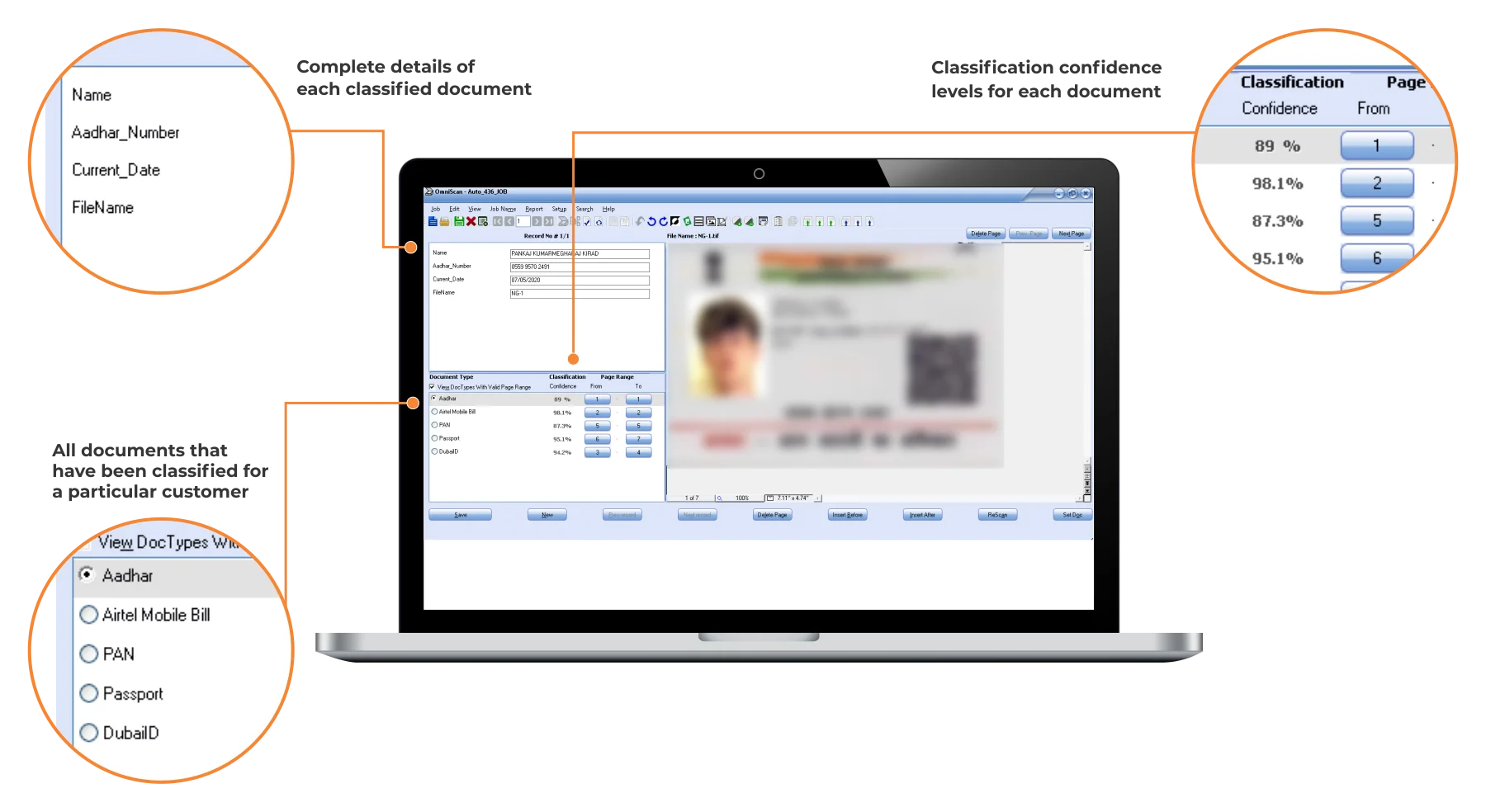
Document Identification and Organization
Document Type Identification – Detect and process large volumes of structured, semi-structured, and unstructured documents efficiently.
Automated Organization & Classification – Eliminate manual, labor-intensive processes with automated sequencing and classification of documents.
Layout, Object, and Content-based Classification
Layout & Object-Based Classification – Classify structured documents using visual patterns, logos, symbols, and other design elements.
Content-Based Classification – Organize semi-structured and unstructured documents by analyzing keywords and identifying relationships within text.
Machine Learning based Classification
Trainable Machine Learning Models – Continuously improve document classification accuracy with adaptive ML technology.
Dedicated Model Training Tool – Easily create, train, and deploy new classification models for evolving business needs.
Streamlined Service Request Processing
Document Classification for Service Requests – Group and classify customer documents to accelerate service request processing.
Seamless Integration – Connect easily with core business applications, content management platforms, and document capture tools for streamlined workflows.
Smart Document Capture Tools
Eliminate Manual Segregation – Remove the need for separator pages with automated document handling.
AI-Powered Bulk Classification – Automatically classify documents imported in bulk using intelligent AI algorithms.
Data Confidentiality and Compliance
Compliance-Ready Document Classification – Classify documents while adhering to strict confidentiality and compliance standards, including HIPAA, PCI DSS, and GDPR.
Litigation Document Management – Organize and classify documents for eDiscovery, legal hold, investigations, and other legal processes.
Transform Your Content Management Today
Manage billions of documents, automate workflows, and ensure compliance—all in one platform. Discover how a Content Services Platform can transform your content management.































